写在前面
- 生活中你一定听说过——能者多劳
- 作为 Java 程序员,你一定听过——这个功能请求慢,能加一层缓存或优化一下 SQL 吗?
- 看过中国古代神话故事的也一定听过——天上一天,地上一年

一切设计来源于生活,上一章 中有讲过,作为”资本家”,你要尽可能的榨取 CPU,内存与 IO 的剩余价值,但三者完成任务的速度相差很大,CPU > 内存 > IO,CPU 是天,那内存就是地,内存是天,那 IO 就是地,那怎样平衡三者,提升整体速度呢?
- CPU 增加缓存,还不止一层缓存,平衡内存的慢
- CPU 能者多劳,通过分时复用,平衡 IO 的速度差异
- 优化编译指令
上面的方式貌似解决了木桶短板问题,但同时这种解决方案也伴随着产生新的可见性,原子性,和有序性的问题,且看
可见性
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性
谈到可见性,要先引出 JMM (Java Memory Model) 概念, 即 Java 内存模型,Java 内存模型规定,将所有的变量都存放在 主内存 中,当线程使用变量时,会把主内存里面的变量 复制 到自己的工作空间或者叫作 私有内存 ,线程读写变量时操作的是自己工作内存中的变量。
用 Git 的工作流程理解上面的描述就很简单了,Git 远程仓库就是主内存,Git 本地仓库就是自己的工作内存
文字描述有些抽象,我们来图解说明:
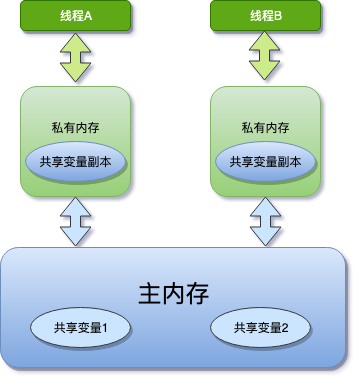
看这个场景:
- 主内存中有变量 x,初始值为 0
- 线程 A 要将 x 加 1,先将 x=0 拷贝到自己的私有内存中,然后更新 x 的值
- 线程 A 将更新后的 x 值回刷到主内存的时间是不固定的
- 刚好在线程 A 没有回刷 x 到主内存时,线程 B 同样从主内存中读取 x,此时为 0,和线程 A 一样的操作,最后期盼的 x=2 就会编程 x=1
这就是线程可见性的问题
JMM 是一个抽象的概念,在实际实现中,线程的工作内存是这样的:
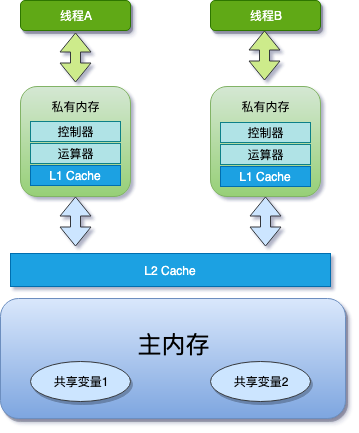
为了平衡内存/IO 短板,会在 CPU 上增加缓存,每个核都只有自己的一级缓存,甚至有一个所有 CPU 都共享的二级缓存,就是上图的样子了,都说这么设计是硬件同学留给软件同学的一个坑,但能否跳过去这个坑也是衡量软件同学是否走向 Java 进阶的关键指标吧……
小提示
从上图中你也可以看出,在 Java 中,所有的实例域,静态域和数组元素都存储在堆内存中,堆内存在线程之间共享,这些在后续文章中都称之为「共享变量」,局部变量,方法定义参数和异常处理器参数不会在线程之间共享,所以他们不会有内存可见性的问题,也就不受内存模型的影响
一句话,要想解决多线程可见性问题,所有线程都必须要刷取主内存中的变量
怎么解决可见性问题呢?Java 关键字 volatile 帮你搞定,后续章节会分析……
原子性
原子(atom)指化学反应不可再分的基本微粒,原子性操作你应该能感受到其含义:
所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch
小品「钟点工」有一句非常经典的台词,要把大象装冰箱,总共分几步?
来看一小段程序:

多线程情况下能得到我们期盼的 count = 20000 的值吗? 也许有同学会认为,线程调用的 counter 方法只有一个 count++ 操作,是单一操作,所以是原子性的,非也。在线程第一讲中说过我们不能用高级语言思维来理解 CPU 的处理方式,count++ 转换成 CPU 指令则需要三步,通过下面命令解析出汇编指令等信息:
1 | javap -c UnsafeCounter |
截取 counter 方法的汇编指令来看:
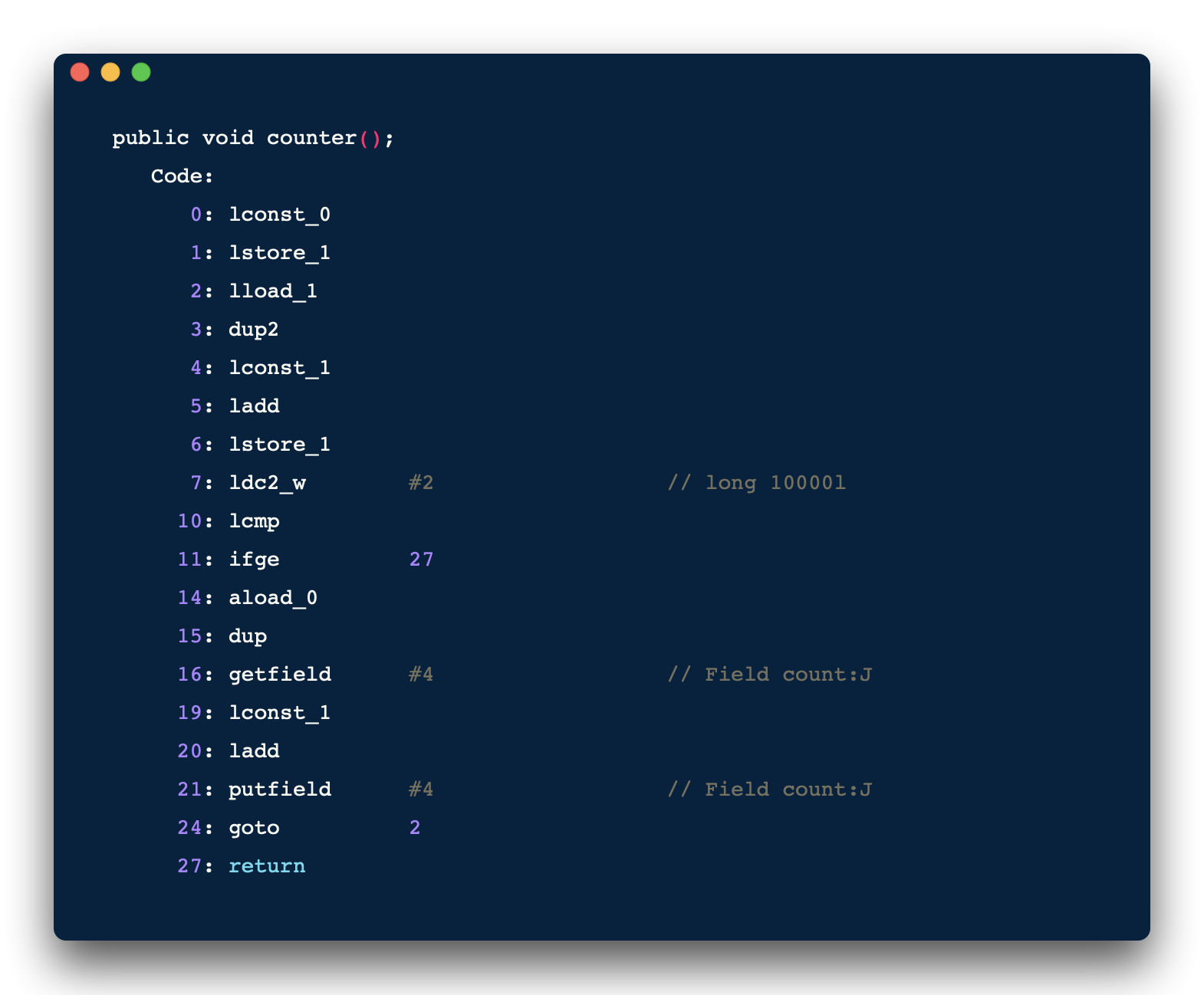
解释一下上面的指令,
16 : 获取当前 count 值,并且放入栈顶
19 : 将常量 1 放入栈顶
20 : 将当前栈顶中两个值相加,并把结果放入栈顶
21 : 把栈顶的结果再赋值给 count
由此可见,简单的 count++ 不是一步操作,被转换为汇编后就不具备原子性了,就好比大象装冰箱,其实要分三步:
第一步,把冰箱门打开;第二步,把大象放进去;第三步,把冰箱门带上
结合 JMM 结构图理解,说明一下为什么很难得到 count=20000 的结果: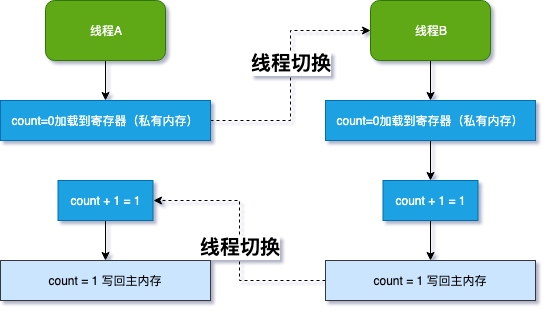
多线程计数器,如何保证多个操作的原子性呢?最粗暴的方式是在方法上加 synchronized 关键字,比如这样:
问题是解决了,如果 synchronized 是万能良方,那么也许并发就没那么多事了,可以靠一个 synchronized 走天下了,事实并不是这样,synchronized 是独占锁 (同一时间只能有一个线程可以调用),没有获取锁的线程会被阻塞;另外也会带来很多线程切换的上下文开销
所以 JDK 中就有了非阻塞 CAS (Compare and Swap) 算法实现的原子操作类 AtomicLong 等工具类,看过源码的同学也许会发现一个共同特点,所有原子类中都有下面这样一段代码:
1 | private static final Unsafe unsafe = Unsafe.getUnsafe(); |
这个类是 JDK 的 rt.jar 包中的 Unsafe 类提供了 硬件级别 的原子性操作,类中的方法都是 native 修饰的,后面介绍原子类之前也会先说明这个类中的几个方法,这里先简单介绍有个印象即可。
有同学不理解我刚刚提到的线程上下文切换开销很大是什么意思,举 2个例子你就懂了:
- 你(CPU)在看两本书(两个线程),看第一本书很短时间后要去看第二本书,看第二本书很短时间后又回看第一本书,并要精确的记得看到第几行,当初看到了什么(CPU 记住线程级别的信息),当让你 “同时” 看 10 本甚至更多,切换的开销就很大了吧
- 综艺节目中有很多游戏,让你一边数钱,又要一边做其他的事,最终保证多样事情都做正确,大脑开销大不大,你试试就知道了😊
有序性
生活中你问候他人「吃了吗你?」和「你吃了吗?」是一个意思,你写的是下面程序:
1 | a = 1; |
编译器优化后可能就变成了这样:
1 | b = 2; |
这个情况,编译器调整了语句顺序没什么影响,但编译器 擅自 优化顺序,就给我们埋下了雷,比如应用双重检查方式实现的单例

一切又很完美是不是,非也,问题出现在 instance = new Singleton();,这 1 行代码转换成了 CPU 指令后又变成了 3 个,我们理解 new 对象应该是这样的:
- 分配一块内存 M
- 在内存 M 上初始化 Singleton 对象
- 然后 M 的地址赋值给 instance 变量
但编译器擅自优化后可能就变成了这样:
- 分配一块内存 M
- 然后将 M 的地址赋值给 instance 变量
- 在内存 M 上初始化 Singleton 对象
首先 new 对象分了三步,给 CPU 留下了切换线程的机会;另外,编译器优化后的顺序可能导致问题的发生,来看:
- 线程 A 先执行 getInstance 方法,当执行到指令 2 时,恰好发生了线程切换
- 线程 B 刚进入到 getInstance 方法,判断 if 语句 instance 是否为空
- 线程 A 已经将 M 的地址赋值给了 instance 变量,所以线程 B 认为 instance 不为空
- 线程 B 直接 return instance 变量
- CPU 切换回线程 A,线程 A 完成后续初始化内容
我们还是画个图说明一下:
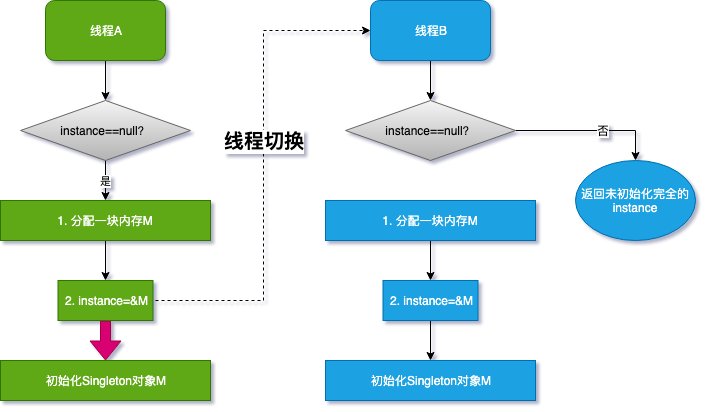
如果线程 A 执行到第 2 步,线程切换,由于线程 A 没有把红色箭头执行完全,线程 B 就会得到一个未初始化完全的对象,访问 instance 成员变量的时候就可能发生 NPE,如果将变量 instance 用 volatile 或者 final 修饰(涉及到类的加载机制,问题就解决了.
总结
你所看到的程序并不一定是编译器优化/编译后的 CPU 指令,大象装冰箱是是个程序,但其隐含三个步骤,学习并发编程,你要按照 CPU 的思维考虑问题,所以你需要深刻理解 可见性/原子性/有序性 ,这是产生并发 Bug 的源头
本节说明了三个问题,下面的文章也会逐个分析解决以上问题的办法,以及相对优的方案
灵魂追问
- 为什么用 final 修饰的变量就是线程安全的了呢?
- 你会经常查看 CPU 汇编指令吗?
- 如果让你写单例,你通常会采用哪种实现?
