写在前面 上一篇文章谈到了可见性/原子性/有序性三个问题,这些问题通常违背我们的直觉和思考模式,也就导致了很多并发 Bug
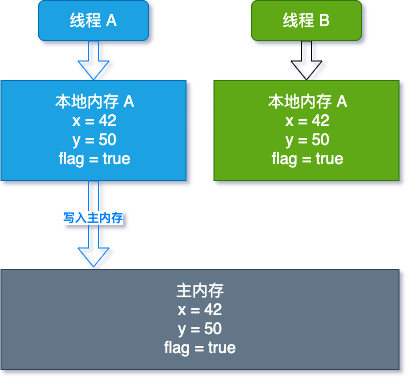
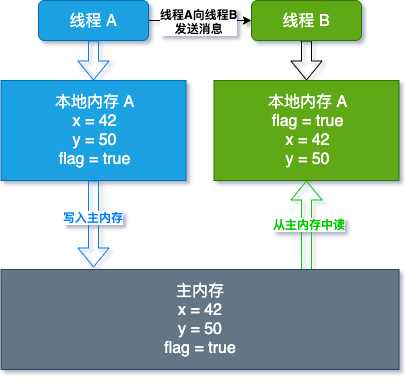
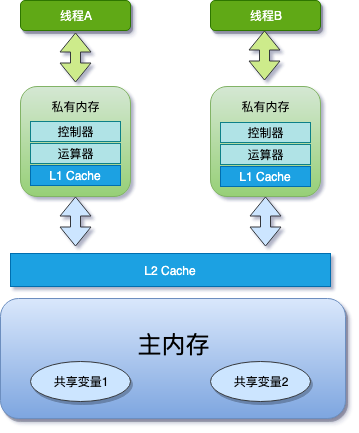
为了解决 CPU,内存,IO 的短板,增加了缓存,但这导致了可见性问题
编译器/处理器擅自优化 ( Java代码在编译后会变成 Java 字节码, 字节码被类加载器加载到 JVM 里, JVM执行字节码, 最终需要转化为汇编指令在 CPU 上执行) ,导致有序性问题
初衷是好的,但引发了新问题,最有效的办法就禁止缓存和编译优化,问题虽然能解决,但「又回到最初的起点,呆呆地站在镜子前」是很尴尬的,我们程序的性能就堪忧了.
解决方案
作为我们程序猿不想写出 bug 影响 KPI,所以希望内存模型易于理解、易于编程。这就需要基于一个强内存模型 来编写代码
作为编译器和处理器不想让外人说它处理速度很慢,所以希望内存模型对他们束缚越少越好,可以由他们擅自优化 ,这就需要基于一个弱内存模型
俗话说:「没有什么事是开会解决不了的,如果有,那就再开一次」😂
JSR-133 的专家们就有了新想法,既然不能完全禁止缓存和编译优化,那就按需 禁用缓存和编译优化,按需就是要加一些约束,约束中就包括了上一篇文章简单提到过的 volatile,synchronized,final 三个关键字,同时还有你可能听过的 Happens-Before 原则(包含可见性和有序性的约束),Happens-before 规则也是本章的主要内容
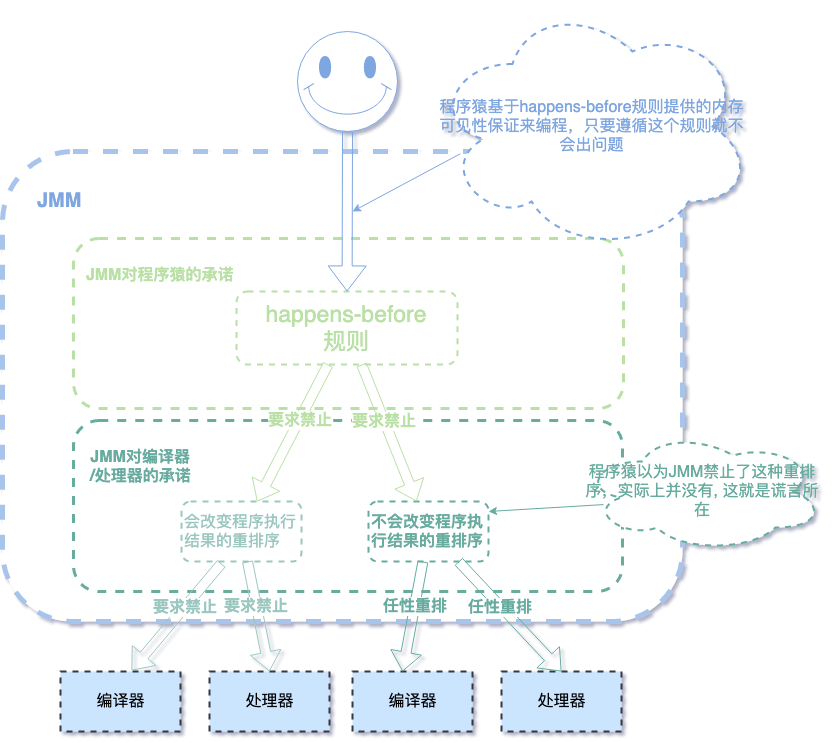
为了满足二者的强烈需求,照顾到双方的情绪,于是乎: JMM 就对程序猿说了一个善意的谎言: 「会严格遵守 Happpen-Befores 规则,不会重排序」让程序猿放心,私下却有自己的策略:
对于会改变程序执行结果的重排序,JMM要求编译器和处理器必须禁止这种重排序。
对于不会改变程序执行结果的重排序, JMM对编译器和处理器不做要求 (JMM允许这种重排序)。
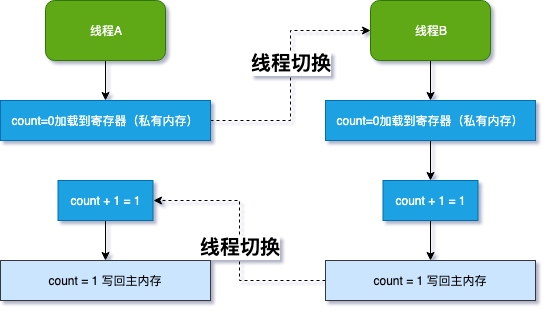
我们来用个图说明一下:
这就是那个善意的谎言,虽是谎言,但还是照顾到了程序猿的利益,所以我们只需要了解 happens-before 规则就能得到保证 (图画了好久,不知道是否说明了谎言的所在😅,欢迎留言)
Happens-before Happens-before 规则主要用来约束两个操作,两个操作之间具有 happens-before 关系, 并不意味着前一个操作必须要在后一个操作之前执行,happens-before 仅仅要求前一个操作(执行的结果)对后一个操作可见 , (the first is visible to and ordered before the second)
说了这么多,先来看一小段代码带你逐步走进 Happen-Befores 原则,看看是怎样用该原则解决 可见性 和 有序性 的问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 class ReorderExample int x = 0 ; boolean flag = false ; public void writer () x = 42 ; flag = true ; } public void reader () if (flag) { System.out.println(x); } } }
假设 A 线程执行 writer 方法,B 线程执行 reader 方法,打印出来的 x 可能会是 0,上一篇文章说明过: 因为代码 1 和 2 没有数据依赖 关系,所以可能被重排序
所以,线程 A 将 flag = true 写入但没有为 x 重新赋值时 ,线程 B 可能就已经打印了 x 是 0
那么为 flag 加上 volatile 关键字试一下:
1 volatile boolean flag = false ;
即便加上了 volatile 关键字,这个问题在 java1.5 之前还是没有解决,但 java1.5 和其之后的版本对 volatile 语义做了增强 ,问题得以解决,这就离不开 Happens-before 规则的约束了,总共有 6 个规则,且看
程序顺序性规则
一个线程中 的每个操作, happens-before 于该线程中的任意后续操作
这个规则是一个基础规则,happens-before 是多线程的规则,所以要和其他规则约束在一起才能体现出它的顺序性,别着急,继续向下看
volatile变量规则
对一个 volatile 域的写, happens-before 于任意后续对这个 volatile 域的读
我将上面的程序添加两行代码作说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class ReorderExample private int x = 0 ; private int y = 1 ; private volatile boolean flag = false ; public void writer () x = 42 ; y = 50 ; flag = true ; } public void reader () if (flag){ System.out.println("x:" + x); System.out.println("y:" + y); } } }
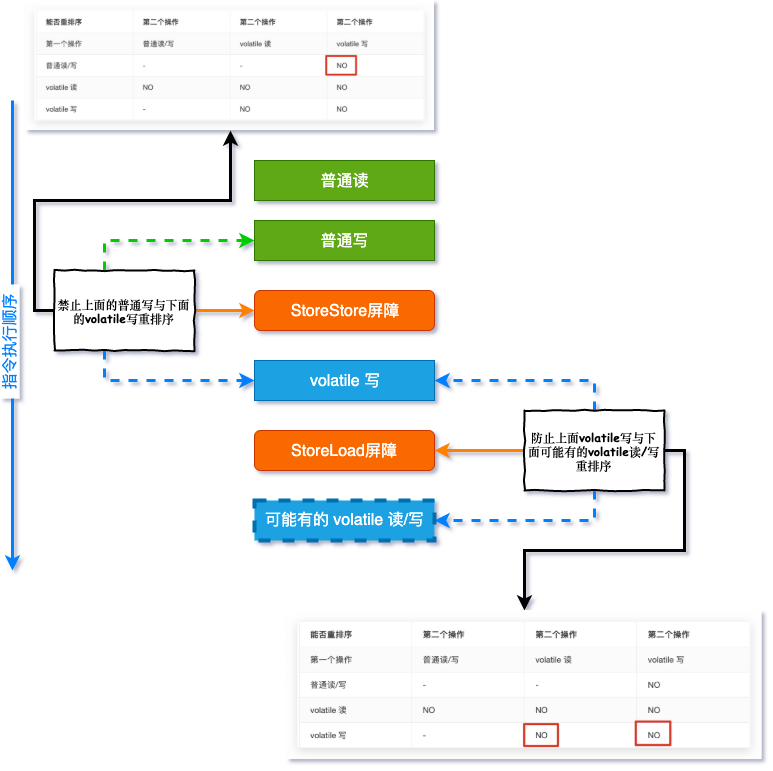
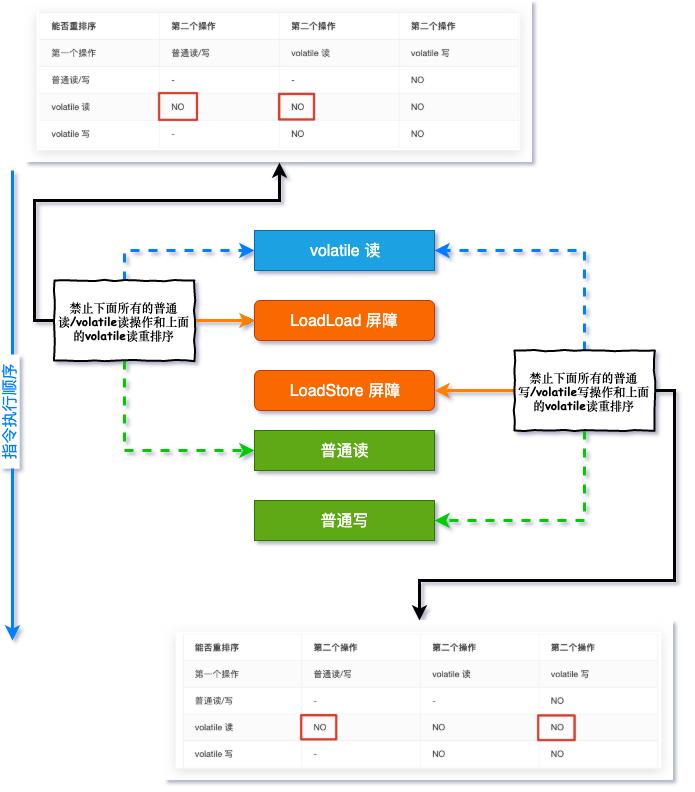
这里涉及到了 volatile 的内存增强语义,先来看个表格:
能否重排序
第二个操作
第二个操作
第二个操作
第一个操作
普通读/写
volatile 读
volatile 写
普通读/写
-
-
NO
volatile 读
NO
NO
NO
volatile 写
-
NO
NO
从这个表格 最后一列 可以看出:
如果第二个操作为 volatile 写,不管第一个操作是什么,都不能重排序,这就确保了 volatile 写之前的操作不会被重排序到 volatile 写之后 程序顺序性规则 是不是就已经关联起来了呢?
从这个表格的 倒数第二行 可以看出:
如果第一个操作为 volatile 读,不管第二个操作是什么,都不能重排序,这确保了 volatile 读之后的操作不会被重排序到 volatile 读之前
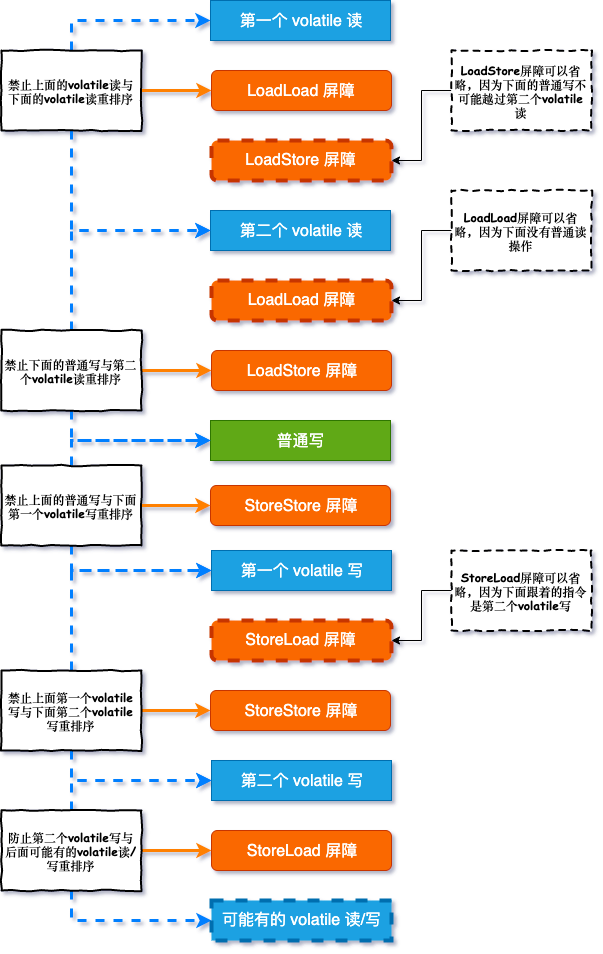
volatile 内存语义的实现是应用到了 「内存屏障」,因为这完全够单独写一章的内容,这里为了不掩盖主角 Happens-before 的光环,保持理解 Happens-before 的连续性,先不做过多说明
到这里,看这个规则,貌似也没解决啥问题,因为它还要联合第三个规则才起作用
传递性规则
如果 A happens-before B, 且 B happens-before C, 那么 A happens-before C
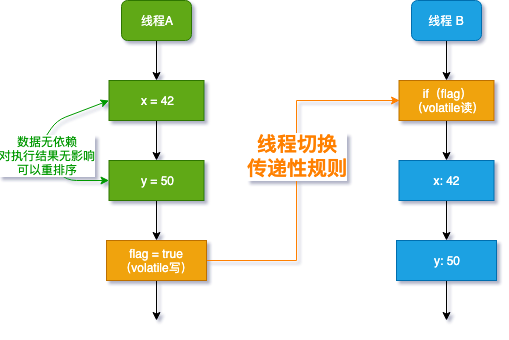
从上图可以看出
x =42 和 y = 50 Happens-before flag = true, 这是规则 1 写变量(代码 3) flag=true Happens-before 读变量(代码 4) if(flag),这是规则 2
根据规则 3 传递性规则,x =42 Happens-before 读变量 if(flag)
谜案要揭晓了 : 如果线程 B 读到了 flag 是 true,那么 x =42 和 y = 50 对线程 B 就一定可见了,这就是 Java1.5 的增强 (之前版本是可以普通变量写和 volatile 变量写的重排序的)
通常上面三个规则是一种联合约束,到这里你懂了吗?规则还没完,继续看
监视器锁规则
对一个锁的解锁 happens-before 于随后对这个锁的加锁
这个规则我觉得你应该最熟悉了,就是解释 synchronized 关键字的,来看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class SynchronizedExample private int x = 0 ; public void syncBlock () synchronized (SynchronizedExample.class){ x = 1 ; } } public synchronized void syncMethod () x = 2 ; } }
先获取锁的线程,对 x 赋值之后释放锁,另外一个再获取锁,一定能看到对 x 赋值的改动,就是这么简单,请小伙伴用下面命令查看上面程序,看同步块和同步方法被转换成汇编指令有何不同?
1 javap -c -v SynchronizedExample
这和 synchronized 的语义相关,小伙伴可以先自行了解一下,锁的内容时会做详细说明
start()规则
如果线程 A 执行操作 ThreadB.start() (启动线程B), 那么 A 线程的 ThreadB.start() 操作 happens-before 于线程 B 中的任意操作,也就是说,主线程 A 启动子线程 B 后,子线程 B 能看到主线程在启动子线程 B 前的操作,看个程序就秒懂了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class StartExample private int x = 0 ; private int y = 1 ; private boolean flag = false ; public static void main (String[] args) throws InterruptedException StartExample startExample = new StartExample(); Thread thread1 = new Thread(startExample::writer, "线程1" ); startExample.x = 10 ; startExample.y = 20 ; startExample.flag = true ; thread1.start(); System.out.println("主线程结束" ); } public void writer () System.out.println("x:" + x ); System.out.println("y:" + y ); System.out.println("flag:" + flag ); } }
运行结果:
1 2 3 4 5 6 主线程结束 x:10 y:20 flag:true Process finished with exit code 0
线程 1 看到了主线程调用 thread1.start() 之前的所有赋值结果,这里没有打印「主线程结束」,你知道为什么吗?这个守护线程知识有关系
join()规则
如果线程 A 执行操作 ThreadB.join() 并成功返回, 那么线程 B 中的任意操作 happens-before 于线程 A 从 ThreadB.join() 操作成功返回,和 start 规则刚好相反 ,主线程 A 等待子线程 B 完成,当子线程 B 完成后,主线程能够看到子线程 B 的赋值操作,将程序做个小改动,你也会秒懂的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class JoinExample private int x = 0 ; private int y = 1 ; private boolean flag = false ; public static void main (String[] args) throws InterruptedException JoinExample joinExample = new JoinExample(); Thread thread1 = new Thread(joinExample::writer, "线程1" ); thread1.start(); thread1.join(); System.out.println("x:" + joinExample.x ); System.out.println("y:" + joinExample.y ); System.out.println("flag:" + joinExample.flag ); System.out.println("主线程结束" ); } public void writer () this .x = 100 ; this .y = 200 ; this .flag = true ; } }
运行结果:
1 2 3 4 5 6 复制x:100 y:200 flag:true 主线程结束 Process finished with exit code 0
「主线程结束」这几个字打印出来喽,依旧和线程何时退出有关系
总结
Happens-before 重点是解决前一个操作结果对后一个操作可见 ,相信到这里,你已经对 Happens-before 规则有所了解,这些规则解决了多线程编程的可见性与有序性问题,但还没有完全解决原子性问题(除了 synchronized)start 和 join 规则也是解决主线程与子线程通信的方式之一
从内存语义的角度来说, volatile 的写-读与锁的释放-获取有相同的内存效果;volatile 写和锁的释放有相同的内存语义; volatile 读与锁的获取有相同的内存语义,⚠️⚠️⚠️(敲黑板了) volatile 解决的是可见性问题,synchronized 解决的是原子性问题,这绝对不是一回事,后续文章也会说明
灵魂追问
同步块和同步方法在编译成 CPU 指令后有什么不同?
线程有 Daemon(守护线程)和非 Daemon 线程,你知道线程的退出策略吗?
关于 Happens-before 你还有哪些疑惑呢?